

در هدوپ، DataNode یک جزء کلیدی سیستم فایل توزیع شده HDFS (Hadoop Distributed File System) است. وظیفه اصلی DataNode ذخیره سازی واقعی داده ها در گره های مختلف یک خوشه هدوپ است. در مقابل، NameNode مسئول مدیریت متادیتا و هماهنگی بین DataNode ها می باشد.
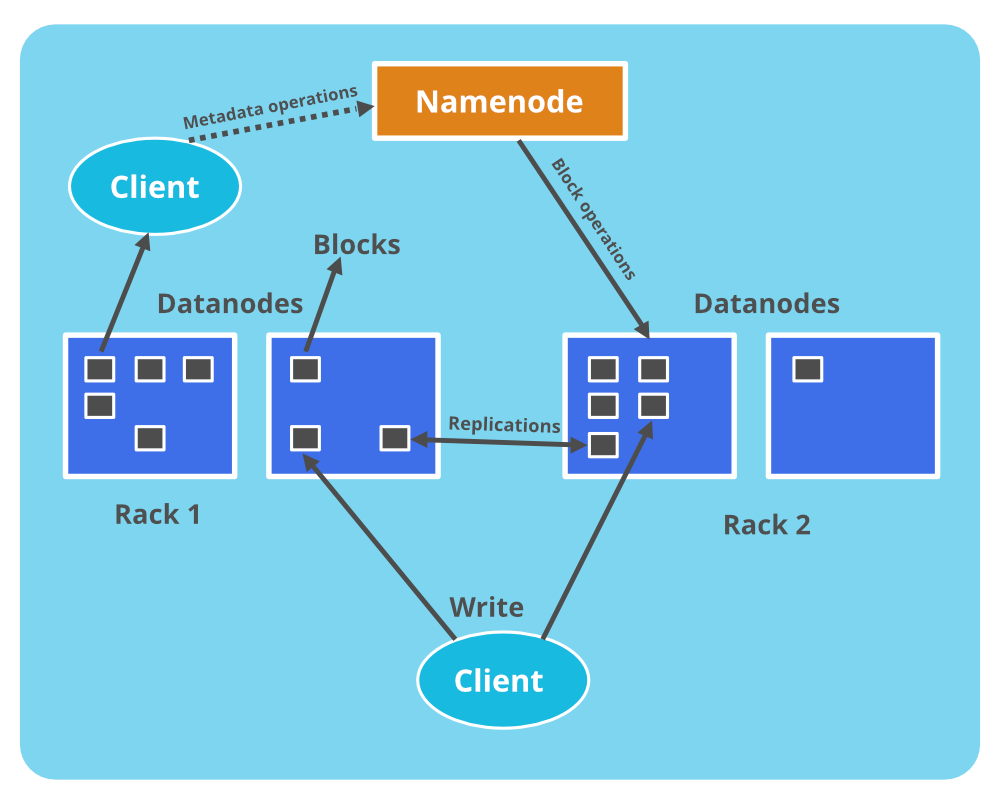
موارد زیر در تصویر نشان داده شدهاند:
- DataNode: گرهای در خوشه Hadoop که دادهها را ذخیره میکند.
- NameNode: گرهای در خوشه Hadoop که متادیتای مربوط به دادهها را ذخیره میکند.
- Block: واحد ذخیرهسازی دادهها در Hadoop.
- Rack: مجموعهای از DataNodeها که در یک مکان فیزیکی قرار دارند.
نحوه کار DataNode:
- DataNode به طور دورهای با NameNode ارتباط برقرار میکند تا لیستی از بلوکهایی را که باید ذخیره کند، دریافت کند.
- DataNode دادهها را در بلوکها ذخیره میکند.
- DataNode به NameNode گزارش میدهد که کدام بلوکها را ذخیره کرده است.
- NameNode متادیتای مربوط به بلوکها را ذخیره میکند، مانند اینکه کدام DataNodeها کدام بلوکها را ذخیره میکنند.
وظایف DataNode:
- ذخیره دادهها
- گزارشدهی به NameNode
- تکرار بلوکها در صورت خرابی یک DataNode
در اینجا می توان گفت DataNode نقش یک سرور ذخیره سازی محلی را بازی می کند و وظایف زیر را بر عهده دارد:
- دریافت و ذخیره سازی داده ها: هنگامی که برنامه های کاربردی یا ابزارهای مدیریت داده ها اقدام به نوشتن داده در HDFS می کنند، DataNode ها دستور دریافت بلوک های داده (معمولا به اندازه 64 مگابایت) را دریافت کرده و آنها را بر روی دیسک محلی خود ذخیره می کنند.
- حفظ یکپارچگی داده ها: هر DataNode نسخه ای از هر بلوک داده را به صورت تکرار شده (replicated) نگه می دارد تا در صورت خرابی یک گره، داده ها از دست نروند. تعداد تکرارها توسط پیکربندی سیستم تعیین می شود.
- بازیابی داده ها: هنگامی که برنامه های کاربردی نیاز به خواندن داده از HDFS دارند، با NameNode ارتباط برقرار می کنند تا مکان بلوک های داده را بدست آورند. سپس، برنامه به طور مستقیم با DataNode های مربوطه ارتباط برقرار می شود و داده ها را مستقیما از آنها بازیابی می کند.
- گزارش وضعیت: هر DataNode به طور دوره ای گزارش وضعیت خود، از جمله فضای دیسک در دسترس، میزان استفاده از CPU و حافظه، و وضعیت سلامت بلوک های داده را به NameNode ارسال می کند.
ویژگی های DataNode:
- مقیاس پذیری: می توان گره های DataNode بیشتری را به خوشه اضافه کرد تا ظرفیت ذخیره سازی و توان پردازش افزایش یابد.
- مقاومت در برابر خطا: تکرار بلوک های داده باعث می شود که حتی در صورت خرابی یک گره، داده ها همچنان برای خواندن و نوشتن در دسترس باشند.
- مقرون به صرفه: DataNode می تواند بر روی سخت افزار معمولی اجرا شود که به مقرون به صرفه بودن سیستم کمک می کند.
- انعطاف پذیر: DataNode می تواند بر روی سیستم عامل های مختلف (مانند لینوکس، ویندوز) اجرا شود.



DataNode جزء اصلی HDFS (سیستم فایل توزیع شده Hadoop) است که وظایف ذخیره سازی و مدیریت بلوک های داده را بر عهده دارد.
مقیاس پذیری DataNode ها برای اطمینان از عملکرد روان و کارآمد HDFS در حجم عظیم داده ها از اهمیت بالایی برخوردار است.
مقیاس پذیری افقی:
مقیاس پذیری افقی به افزودن گره های جدید به خوشه HDFS برای افزایش ظرفیت ذخیره سازی و توان پردازش اشاره دارد. DataNode ها در هر گره جدید نصب و اجرا می شوند و ظرفیت ذخیره سازی را به طور خطی افزایش می دهند.
مزایای مقیاس پذیری افقی:
افزایش ظرفیت ذخیره سازی: با افزودن DataNode های جدید می توان حجم داده های ذخیره شده در HDFS را به طور قابل توجهی افزایش داد.
بهبود عملکرد: با توزیع داده ها در DataNode های بیشتر، بار پردازش به طور متعادل توزیع می شود و منجر به بهبود عملکرد I/O و پردازش می شود.
افزایش در دسترس پذیری: در صورت خرابی یک DataNode، DataNode های دیگر می توانند به ارائه داده ها ادامه دهند، که به طور کلی در دسترس پذیری HDFS را افزایش می دهد.
ملاحظات مربوط به مقیاس پذیری افقی:
هزینه: افزودن گره های جدید به خوشه HDFS می تواند هزینه های سخت افزاری و نرم افزاری را افزایش دهد.
پیچیدگی: مدیریت خوشه HDFS با تعداد زیادی DataNode می تواند پیچیده تر باشد.
محدودیت های شبکه: پهنای باند شبکه می تواند به یک عامل محدود کننده در هنگام مقیاس پذیری افقی تبدیل شود، به خصوص در حجم عظیم داده ها.
مقیاس پذیری عمودی:
مقیاس پذیری عمودی به افزایش منابع محاسباتی و ذخیره سازی در هر DataNode موجود اشاره دارد. این می تواند شامل ارتقای CPU، RAM، دیسک های ذخیره سازی یا سایر اجزای سخت افزاری باشد.
مزایای مقیاس پذیری عمودی:
هزینه: مقیاس پذیری عمودی معمولاً از نظر هزینه مقرون به صرفه تر از مقیاس پذیری افقی است، زیرا نیازی به افزودن گره های جدید به خوشه نیست.
پیچیدگی: مدیریت خوشه HDFS با DataNode های کمتر پیچیده تر است.
بهبود عملکرد: ارتقای منابع در هر DataNode می تواند منجر به بهبود عملکرد I/O و پردازش در سطح DataNode شود.
ملاحظات مربوط به مقیاس پذیری عمودی:
محدودیت های سخت افزاری: در نهایت محدودیتی برای ارتقای منابع در هر DataNode وجود دارد که توسط قابلیت های سخت افزاری آن گره تعیین می شود.
عدم تعادل بار: ارتقای DataNode های خاص می تواند منجر به عدم تعادل بار در خوشه HDFS شود، به خصوص در حجم عظیم داده ها.
انتخاب بین مقیاس پذیری افقی و عمودی:
انتخاب بین مقیاس پذیری افقی و عمودی به عوامل مختلفی از جمله حجم داده ها، الزامات عملکرد، بودجه و تخصص فنی بستگی دارد. به طور کلی، مقیاس پذیری افقی برای خوشه های HDFS با حجم عظیم داده ها مناسب تر است، در حالی که مقیاس پذیری عمودی می تواند برای خوشه های کوچکتر یا برای ارتقای عملکرد خاص DataNode ها مفید باشد.
نکات مهم:
HDFS از استراتژی های ترکیبی مقیاس پذیری افقی و عمودی برای بهینه سازی عملکرد و کارایی برای حجم عظیم داده ها پشتیبانی می کند.
ابزارها و تکنیک های مختلفی برای مدیریت و نظارت بر مقیاس پذیری DataNode ها در HDFS موجود است.
انتخاب استراتژی مقیاس پذیری مناسب به طور قابل توجهی بر عملکرد، هزینه و پیچیدگی کلی HDFS تأثیر می گذارد.
در نهایت، درک عمیق از مفاهیم و چالش های مربوط به مقیاس پذیری DataNode ها برای اتخاذ تصمیمات آگاهانه در مورد نحوه ارتقای HDFS برای نیازهای خاص شما ضروری است.
در HDFS، DataNode ها نقش مهمی در ذخیره سازی و مدیریت بلوک های داده در سراسر خوشه ایفا می کنند. برای اطمینان از در دسترس بودن و پایداری داده ها، DataNode ها با استفاده از تکنیک های مختلفی در برابر خطا مقاوم سازی می شوند.
مهمترین مکانیزم های مقاومت در برابر خطا در DataNode عبارتند از:
1. تکرار بلوک:
هر بلوک داده به طور پیش فرض در سه DataNode کپی می شود. این بدان معناست که اگر یک DataNode از کار بیفتد، دو کپی دیگر از بلوک همچنان در دسترس خواهند بود.
تعداد کپی ها را می توان برای بلوک های خاص پیکربندی کرد تا نیازهای خاص را برآورده کند.
2. تشخیص خرابی:
DataNode ها به طور مداوم با یکدیگر پینگ (ping) می کنند تا از سلامت یکدیگر مطلع شوند.
اگر یک DataNode به پینگ ها پاسخ ندهد، به عنوان معیوب علامت گذاری می شود.
3. بازسازی بلوک:
هنگامی که یک DataNode معیوب شناسایی می شود، بلوک های داده ای که در آن ذخیره شده اند باید بازسازی شوند.
این فرآیند شامل کپی کردن بلوک ها از DataNode های سالم به یک DataNode جدید است.
4. ذخیره سازی داده های فراداده:
اطلاعات مربوط به بلوک های داده، مانند محل ذخیره سازی آنها، در ساختارهای داده به نام “فراداده” ذخیره می شود.
فراداده به صورت تکراری در DataNode های مختلف ذخیره می شود تا در صورت خرابی یک DataNode، دسترس باقی بماند.
5. گزارش دهی:
DataNode ها به طور مداوم وضعیت خود و بلوک های داده ای که ذخیره می کنند را به NameNode گزارش می دهند.
NameNode از این اطلاعات برای پیگیری سلامت کلی خوشه و هماهنگی عملیات مربوط به بلوک داده استفاده می کند.
علاوه بر این مکانیزم ها، HDFS از تکنیک های دیگری مانند:
RAID (Redundant Array of Independent Disks): RAID می تواند برای ذخیره سازی بلوک های داده با استفاده از دیسک های متعدد و افزایش بیشتر مقاومت در برابر خطا استفاده شود.
Checkpointing: NameNode می تواند به طور دوره ای وضعیت خوشه را به دیسک ذخیره کند تا در صورت خرابی NameNode بتوان آن را بازیابی کرد.
با استفاده از این تکنیک های مختلف، HDFS می تواند از دست رفتن داده ها در اثر خرابی DataNode یا سایر مشکلات جلوگیری کند.
نکته:
مقاومت در برابر خطا در HDFS قابل پیکربندی است.
کاربران می توانند سطح مقاومت در برابر خطا را برای نیازهای خاص خود تنظیم کنند.
انتخاب تنظیمات مناسب برای مقاومت در برابر خطا می تواند به تعادل بین عملکرد، هزینه و قابلیت اطمینان کمک کند.
DataNode یکی از اجزای کلیدی سیستم فایل توزیع شده هادوپ (HDFS) است که وظیفه ذخیرهسازی بخشهایی از دادهها (به نام Block) را در سراسر یک خوشه از گرهها بر عهده دارد.
DataNode انعطافپذیر مفهوم جدیدی در HDFS نیست، اما با معرفی قابلیتهای جدید در نسخههای اخیر هادوپ، به ابزاری قدرتمندتر و کارآمدتر برای ذخیرهسازی دادههای حجیم تبدیل شده است.
در اینجا برخی از ویژگیهای کلیدی DataNode انعطافپذیر را شرح میدهیم:
1. ذخیرهسازی ترکیبی:
DataNode انعطافپذیر میتواند از ذخیرهسازی دیسک محلی (HDD) و حافظه SSD به طور همزمان استفاده کند. این امر به کاربران امکان میدهد تا دادههای پرمراجعه را در حافظه SSD سریع ذخیره کنند و دادههای کممصرف را در HDD با هزینهی کمتر ذخیره کنند.
2. ذخیرهسازی ابری:
DataNode انعطافپذیر میتواند از ذخیرهسازی ابری مانند Amazon S3 یا Microsoft Azure Blob Storage برای ذخیرهسازی دادهها استفاده کند. این امر به کاربران امکان میدهد تا از مقیاسپذیری و قابلیت اطمینان ذخیرهسازی ابری بدون نیاز به مدیریت زیرساخت ذخیرهسازی محلی خود بهرهمند شوند.
3. رمزگذاری دادهها:
DataNode انعطافپذیر از رمزگذاری در سطح بلوک برای محافظت از دادهها در برابر دسترسی غیرمجاز پشتیبانی میکند. این امر به کاربران امکان میدهد تا دادههای حساس خود را با خیال راحت در HDFS ذخیره کنند.
4. فشردهسازی دادهها:
DataNode انعطافپذیر از فشردهسازی دادهها برای کاهش فضای ذخیرهسازی مورد نیاز پشتیبانی میکند. این امر به کاربران امکان میدهد تا هزینههای ذخیرهسازی را کاهش داده و از پهنای باند شبکه به طور کارآمدتر استفاده کنند.
5. تعمیر خودکار:
DataNode انعطافپذیر از تعمیر خودکار برای شناسایی و جایگزینی بلوکهای داده خراب پشتیبانی میکند. این امر به کاربران امکان میدهد تا از دست رفتن دادهها و خرابی خوشه جلوگیری کنند.
مزایای استفاده از DataNode انعطافپذیر:
مقیاسپذیری: DataNode انعطافپذیر به کاربران امکان میدهد تا به راحتی ظرفیت ذخیرهسازی خود را با افزودن گرههای جدید به خوشه HDFS افزایش دهند.
قابلیت اطمینان: DataNode انعطافپذیر از قابلیت اطمینان بالایی برخوردار است و از دست رفتن دادهها و خرابی خوشه را به حداقل میرساند.
کارایی: DataNode انعطافپذیر با استفاده از ذخیرهسازی ترکیبی، فشردهسازی دادهها و ذخیرهسازی ابری، عملکرد ذخیرهسازی را بهینه میکند.
هزینه: DataNode انعطافپذیر با استفاده از ذخیرهسازی ابری و فشردهسازی دادهها، هزینههای ذخیرهسازی را کاهش میدهد.
امنیت: DataNode انعطافپذیر با استفاده از رمزگذاری در سطح بلوک، امنیت دادهها را افزایش میدهد.
DataNode انعطافپذیر ابزاری قدرتمند و کارآمد برای ذخیرهسازی دادههای حجیم در HDFS است. با استفاده از قابلیتهای جدیدی که در نسخههای اخیر هادوپ معرفی شدهاند، DataNode انعطافپذیر به کاربران امکان میدهد تا از مزایای مقیاسپذیری، قابلیت اطمینان، کارایی، هزینه و امنیت برای ذخیرهسازی دادههای خود بهرهمند شوند.