

HDFS مخفف Hadoop Distributed File System است، که یک سیستم فایل توزیع شده است و یکی از اجزای اصلی چارچوب نرم افزار Big Data به نام Apache Hadoop (توضیح بیشتر) است. هدف اصلی HDFS ذخیره سازی قابل اعتماد، مقیاس پذیر و مقرون به صرفه مجموعه داده های بسیار بزرگ روی خوشه ای از رایانه ها است.
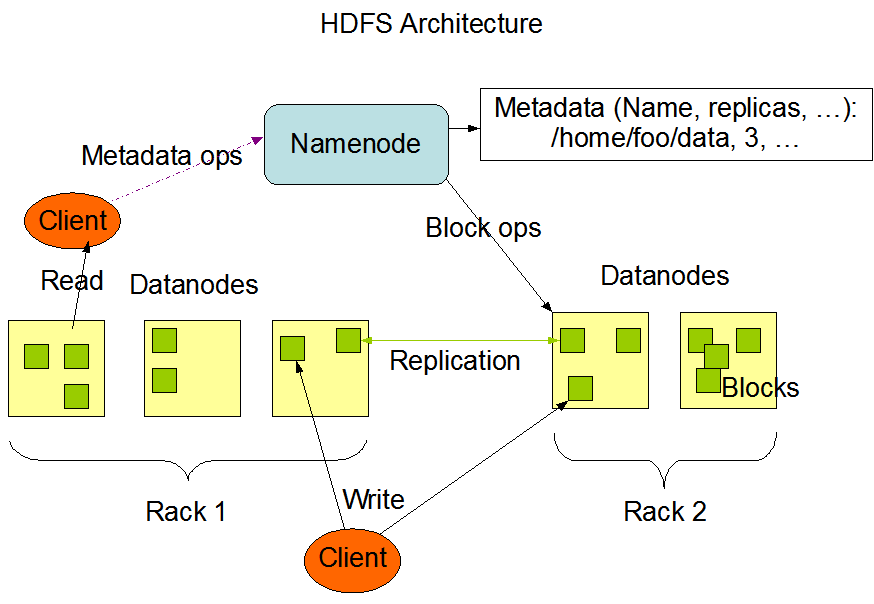
ویژگی های کلیدی HDFS:
- مقیاس پذیری: می تواند مقادیر عظیمی از داده را روی خوشه ای از رایانه ها توزیع کند و با افزودن گره های بیشتر به راحتی مقیاس بندی شود.
- مقاومت در برابر خطا: داده ها را با تکرار آنها در چندین گره از خوشه تکرار می کند، بنابراین اگر یک گره از کار بیفتد، داده ها همچنان در دسترس هستند.
- مقرون به صرفه: از سخت افزار معمولی استفاده می کند که بسیار ارزان تر از سخت افزار تخصصی مورد نیاز برای سایر سیستم های ذخیره سازی است.
- مناسب برای داده های بزرگ: به طور خاص برای ذخیره سازی داده های بزرگ با فرمت هایی مانند متن، فایل های log و داده های حسگرها طراحی شده است.
عملکرد HDFS:
- HDFS یک فایل را به تعدادی بلوک (معمولاً 64 مگابایت) تقسیم می کند و این بلوک ها را در سراسر گره های خوشه توزیع می کند.
- هر بلوک چندین بار تکرار می شود تا در برابر خرابی گره مقاوم باشد.
- یک سیستم نامگذاری مرکزی به نام Namenode مسیر هر بلوک را ردیابی می کند و یک DataNode روی هر گره مسئول ذخیره سازی و بازیابی بلوک ها است.
مقایسه با سیستم های فایل سنتی:
- HDFS در مقایسه با سیستم های فایل سنتی مانند NTFS یا ext4، برای سرعت خواندن و نوشتن بهینه سازی نشده است. اما تمرکز آن بر ذخیره سازی مقرون به صرفه و قابل اعتماد داده های بزرگ است.
- HDFS برای برنامه های کاربردی که نیاز به خواندن و نوشتن مکرر داده ها دارند (مانند پایگاه داده های تراکنشی) مناسب نیست، اما برای کارهایی مانند تجزیه و تحلیل داده های بزرگ و پردازش جریان داده ایده آل است.
کاربردهای HDFS:
- انبارداری داده: ذخیره سازی مقرون به صرفه و ایمن داده های انبار داده.
- تجزیه و تحلیل داده های بزرگ: پردازش مجموعه داده های بزرگ با استفاده از چارچوب هایی مانند MapReduce و Spark.
- پردازش جریان داده: ذخیره و پردازش داده های حسگرها و سایر منابع جریانی.
- حوزه های دیگر: بایگانی داده، یادگیری ماشین و هوش مصنوعی.
امیدوارم این توضیح به شما در درک مفاهیم اساسی HDFS و نحوه عملکرد آن کمک کرده باشد.
HDFS (Hadoop Distributed File System) و Spark هر دو جزء مهمی از اکوسیستم big data هستند، اما به روشهای متفاوتی عمل میکنند:
HDFS: ذخیره سازی داده
هدف: ذخیره سازی مقرون به صرفه و قابل اعتماد برای حجم عظیم داده ها
نوع داده: مناسب برای انواع داده ها، به خصوص داده های غیرساختاریافته
آرکیتکچر (Architecture): سیستم فایل توزیع شده، داده ها را به بخش های کوچک تقسیم کرده و در سراسر خوشه ذخیره می کند
پردازش: HDFS مستقیما داده ها را پردازش نمی کند، بلکه زیرساختی برای ذخیره سازی آنها فراهم می کند
مقیاس پذیری (Scalability): به راحتی با افزودن گره های بیشتر، مقیاس پذیر است
امنیت: امنیت بالایی را با احراز هویت و کنترل دسترسی ارائه می دهد
Spark: پردازش داده
هدف: پردازش سریع و در-حافظه (in-memory) برای حجم عظیم داده ها
نوع داده: برای انواع داده ها مناسب است، اما به طور خاص برای داده های نیمه ساختاریافته و ساختاریافته بهینه شده است
آرکیتکچر: موتور محاسباتی عمومی که می تواند به تنهایی یا روی HDFS اجرا شود
پردازش: داده ها را به صورت موازی در حافظه گره های خوشه پردازش می کند و این امر باعث افزایش سرعت می شود
مقیاس پذیری: با افزودن گره های بیشتر، مقیاس پذیر است، اما پردازش درون حافظه محدودیت هایی را اعمال می کند
امنیت: امنیت کمتری نسبت به HDFS دارد، زیرا بر عهده توسعه دهندگان است که امنیت برنامه های خود را برقرار کنند